블로그 구현 방식으로 Lee의 블로그 형식을 채택했기 때문에 간단한 명령어로 블로그를 시작할 수 있다.
하지만 아주 간단한 블로그 구성으로만 구현이 되어있기 때문에 추가적으로 다른 기능들을 덧붙여나갔다. 그 과정에 대해 소개해보겠다!
해당 방식은 간단하게 나만의 블로그를 구축해나갈 수 있는 좋은 방법이기 때문에 블로그를 손쉽게 만들어보자!
0. 공통 환경 설정
- Node 22.13.0 버전을 사용합니다. (25년 1월 기준 LTS)
- pnpm을 사용합니다.
- TypeScript 5 이상의 버전을 사용합니다.
1. Next.js 블로그 템플릿 사용하기
- 설치하기
pnpm create next-app --example https://github.com/vercel/examples/tree/main/solutions/blog blog-name
- 실행하기
pnpm dev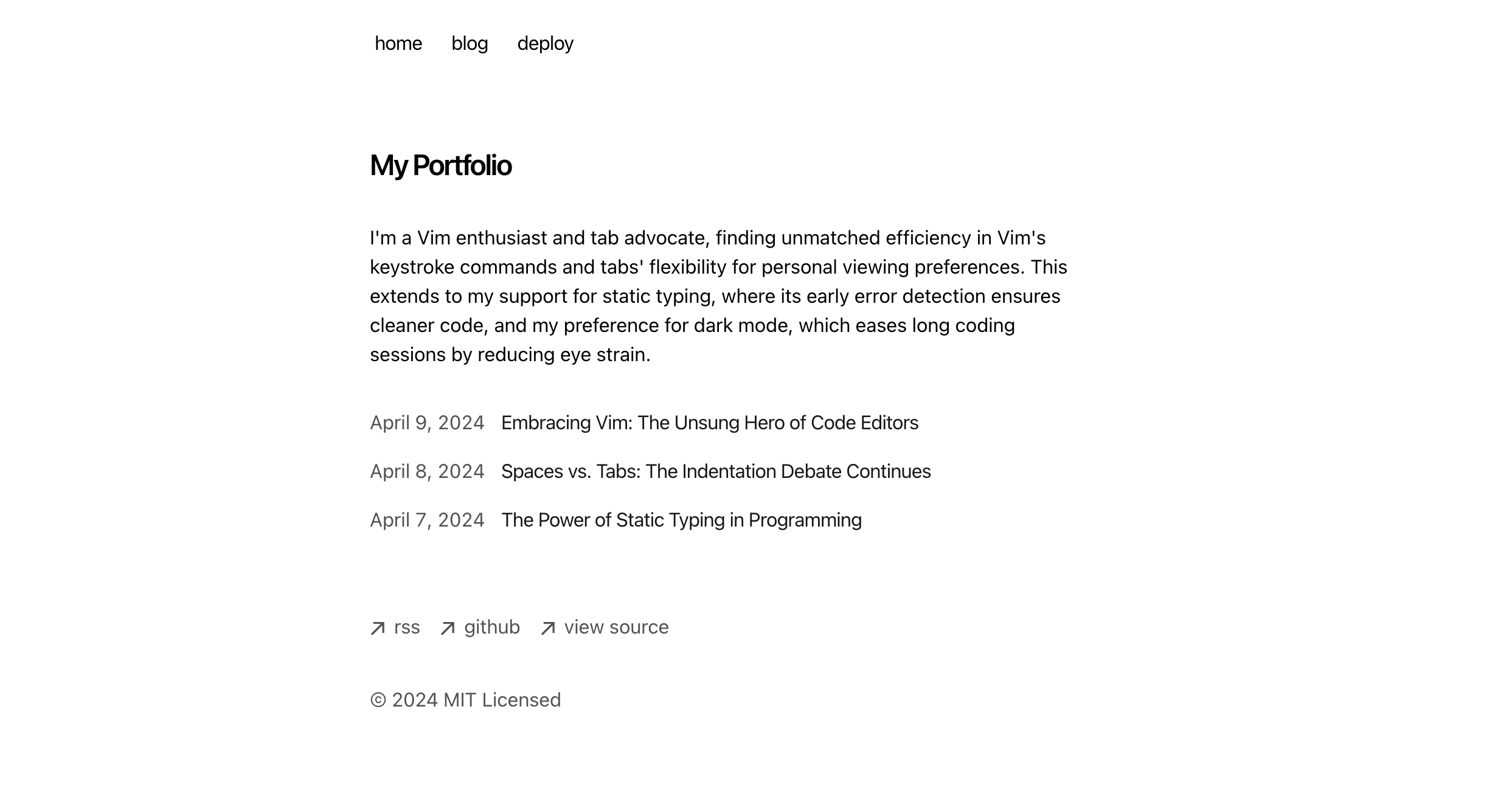
해당 템플릿을 설치하고 실행해보면 베이직한 템플릿이 나오는 것을 확인할 수 있다. 여기서 어떤 기능들이 포함되어있는지 확인해보자.
블로그 템플릿 기능
공식문서에는 다음과 같은 기능들이 포함되어있다고 명시되어있다.
- MDX and Markdown support
- Optimized for SEO (sitemap, robots, JSON-LD schema)
- RSS Feed
- Dynamic OG images
- Syntax highlighting
- Tailwind v4
- Vercel Speed Insights / Web Analytics
- Geist font
블로그 템플릿에서 기본으로 제공하는 기능들을 살펴보자!
MDX
mdx라는 확장자를 갖는 파일에 마크다운 형태로 글을 작성한다. mdx는 md와 jsx를 합친 형태로 마크다운에서 리액트 컴포넌트를 사용할 수 있게 해줘 확장성을 갖는다.
해당 파일은 크게 두가지 영역을 갖는다.
- Front Matter
상단에 3개의 하이픈으로 구분된 영역에 작성되는 값이다.
---
title: 'post title'
publishedAt: "2025-01-09"
summary: "this is post summary"
---이 형식으로 지정된 값은 이후 메타데이터 정보로 활용된다.
<Head>
<title>{title}</title>
<meta name="description" content={summary} />
<meta name="date" content={publishedAt} />
</Head>- Content
Front Matter 아래에는 실제 글의 내용이 담긴다. 마크다운 형태로 작성한다.
# post title
hello world!이렇게 작성된 파일이 파싱 함수에 의해 분석된다.
Parsing
app/blog/utils.ts 파일에서 블로그 포스트 데이터를 파일 시스템에서 가져오고, 메타데이터와 콘텐츠를 추출한 뒤 사용할 수 있도록 가공하는 로직이 포함되어있다.
readMDXFile 함수에서 마크다운 파일을 읽어와 본문을 파싱한다.
그런후 getMDXData 함수에서 dir 디렉토리의 .mdx 파일을 순회하며 다음 데이터를 반환한다.
- metadata: 각 파일의 메타데이터.
- content: 각 파일의 본문.
- slug: 파일명에서 확장자를 제거한 값. (예: post-title.mdx → post-title)
// 파일 경로에서 내용을 읽어와 Frontmatter와 본문을 파싱
function readMDXFile(filePath) {
let rawContent = fs.readFileSync(filePath, "utf-8");
return parseFrontmatter(rawContent);
}
function getMDXData(dir) {
let mdxFiles = getMDXFiles(dir);
return mdxFiles.map((file) => {
let { metadata, content } = readMDXFile(path.join(dir, file));
let slug = path.basename(file, path.extname(file));
return {
metadata,
slug,
content,
};
});
}또한, getBlogPosts 함수에서 블로그 포스트 데이터를 반환한다.
export function getBlogPosts() {
return getMDXData(path.join(process.cwd(), "posts"));
}MDX를 위한 커스텀 컴포넌트들
MDX로 작성된 블로그 내용을 렌더링하기 위해 다양한 컴포넌트를 정의한 커스텀 컴포넌트를 포함시켜 렌더링한다.
export function CustomMDX(props) {
return (
<MDXRemote
{...props}
components={{ ...components, ...(props.components || {}) }}
/>
);
}SEO
SEO 및 Open Graph 데이터를 생성하여 블로그 게시물이 검색 엔진 및 소셜 미디어에서 적절히 표시되도록 설정한다.
// OpenGraph, Twitter 카드 데이터 설정
export function generateMetadata({ params }) {
let post = getBlogPosts().find((post) => post.slug === params.slug);
if (!post) {
return;
}
let {
title,
publishedAt: publishedTime,
summary: description,
image,
} = post.metadata;
let ogImage = image
? image
: `${baseUrl}/og?title=${encodeURIComponent(title)}`;
return {
title,
description,
openGraph: {
title,
description,
type: "article",
publishedTime,
url: `${baseUrl}/blog/${post.slug}`,
images: [
{
url: ogImage,
},
],
},
twitter: {
card: "summary_large_image",
title,
description,
images: [ogImage],
},
};
}sitemap.ts
sitemap.xml 파일은 검색 엔진이 웹사이트를 크롤링할 때 사용하는 중요한 파일로, SEO 최적화에 도움을 준다.
이름처럼 크롤링을 위한 지도를 제공한다.
배포한 URL을 기준으로 모든 경로(동적 블로그 경로, 정적 경로)에 대한 URL을 생성한다.
app/blog/utils에 정의된 함수에서, 모든 블로그 게시글 데이터를 가져와 각 게시글은 slug(URL 경로)와 publishedAt(게시 날짜) 같은 메타데이터를 포함한다.
또한, 템플릿에서는 txt 파일이 아닌 ts 파일로 정의되고 있다. Next.js가 자동으로 이를 처리하고 /sitemap.xml을 생성한다.
즉, 검색 엔진이 사이트맵을 크롤링하고, 블로그 게시글과 페이지를 검색 결과에 노출시킨다.
robots.ts
robots.tsx 파일 또한 검색 엔진 최적화를 위해 필요하다.
검색 엔진 최적화를 위한 크롤링에 대한 규칙을 선언하고, 따라서 크롤링을 할 수 있는지 제어하는 데 사용된다.
또한, 템플릿에서는 txt 파일이 아닌 ts 파일로 정의되고 있다. 이는 동적으로 Robots 객체를 생성해 robots.txt와 같은 역할을 하는 함수를 정의할 수 있는 파일이다.
현재 모든 경로에 대해 크롤링을 허용하도록 규칙을 정의했다. 만약 특정 경로를 차단하고 싶다면, disallow 속성을 추가하면 된다.
rules: [
{
userAgent: '*',
disallow: '/private',
},
],
sitemap: `${baseUrl}/sitemap.xml`,
크롤러가 sitemap.xml을 참고하여 웹사이트의 구조를 이해하고 URL을 효율적으로 크롤링한다.
JSON-LD
검색 엔진이 블로그의 컨텐츠를 잘 해석할 수 있도록 돕는 포맷이다.
/[slug]/page.tsx 경로에 script 태그로 형식에 맞춰 값을 생성하고 있다.
블로그 게시글임을 명시해 검색 엔진에서 블로그 게시글을 찾길 원하는 사람에게 먼저 노출할 수 있도록 하고 있다.
<script
type="application/ld+json"
suppressHydrationWarning
dangerouslySetInnerHTML={{
__html: JSON.stringify({
"@context": "https://schema.org",
"@type": "BlogPosting",
headline: post.metadata.title,
datePublished: post.metadata.publishedAt,
dateModified: post.metadata.publishedAt,
description: post.metadata.summary,
image: post.metadata.image
? `${baseUrl}${post.metadata.image}`
: `/og?titl=${encodeURIComponent(post.metadata.title)}`,
url: `${baseUrl}/blog/${post.slug}`,
author: {
"@type": "Person",
name: "My Portfolio",
},
}),
}}
/>RSS
웹 피드를 위한 XML 기반 형식이다. 콘텐츠 배포와 구독에 사용된다.
이를 적용하면 사용자가 웹사이트를 직접 방문하지 않고도 새로운 콘텐츠를 쉽게 확인할 수 있다.
템플릿에서는 라우트 핸들러로 /rss 경로를 만들어 적용하고 있다. 빌드할 때마다 게시글을 모두 조회해 피드를 구성하고 있다.
OpenGraph 이미지
라우트 핸들러(/og/route.tsx)와 ImageResponse를 조합해서 동적인 OpenGraph 이미지를 생성한다.
og 이미지(동적 이미지)는 URL을 공유했을 시 미리보기 템플릿을 제공한다.
2. Conclusion
코드를 살펴보면서 필자가 원했던 SEO 기능과 메타 데이터가 어떤식으로 적용되는지 알 수 있었다.
또 일반적인 Next.js 블로그를 구현하는 방식을 알아보면서 더욱 다양하고 깊은 지식을 습득할 수 있었다.
Next.js는 프레임워크인지라 레퍼런스가 중요했는데 해당 템플릿을 통해 학습한 방식은 꽤 괜찮은 것 같다.
여기까지 기본 템플릿 구성에 대해 살펴보았다. 여기에서 설정을 변경해줘야 하는 부분이 있다. 어떤 설정들을 변경해줬는지 다음 글에서 다뤄보도록 하겠다!